
At 6pm, I pack my laptop in my bag and walk in the long, silent, and empty corridors of the office. Since the pandemic started, I’ve been one of the few who often comes to the building. Right when I reach the exit, I realize that I have not turned off the lights. The light switch is inconveniently located in the middle of the office. So I say: “Alexa, turn off the lights.” At the distance, I see the circular blue light pulsating, then the lights go off. I leave for the day.
This is nothing short of science fiction, yet here I am talking to a computer powered by artificial intelligence. Alexa, Siri, or the nameless assistants are impressive. They sit quietly in the background and await our instructions. They are not as sophisticated as Samantha, the artificial intelligence in the movie “Her”. They can’t hold a natural conversation, though they can be witty and can even tell jokes.
In this post, I would like to explore how these smart assistants work and how they use AI in the pipeline to complete these tasks for us.
The name
Siri, Alexa, and the others are often referred to as voice assistants. But they go by other names such as smart assistants, smart speakers, or the oldest term and most accurate term, virtual assistant.
What they describe is a device or digital service that you can give a voice command to. Since we are human and tend to anthropomorphize everything, we try to have a conversation with these devices. In this article, we will not address conversation because it is out of scope. However, we will explain how AI can extract intent out of a voice command. It all starts with the trigger word.
The Trigger
In a crowded room, if you want to address a person you have to call them by name. If you just start talking to them before getting their attention, they might hear you but won’t listen to you. There is too much noise, so they’ll assume you are talking to someone else.
It’s the same thing for virtual assistants. They can’t possibly listen to everything being said. If they were always listening, they might hear something that sounds like a command and start executing it. Instead, they only try to listen for the trigger phrase.
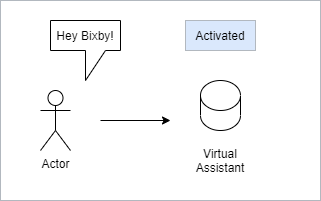
This is where we have our first interaction with AI. More specifically, Machine learning. Companies like Google create a training dataset with thousands or more recordings of the trigger phrase. With enough data, they build a model using that dataset and use a classifier to analyze your voice. The classifier takes a sample recording, let’s say 2 or 3 seconds, then processes it to see if it contains the trigger phrase. This is what happens when your device is idle. It is quietly classifying sample recordings.
Because the device has to respond immediately, the processing is generally done locally on the device, not over the internet. When the trigger word is detected, the device is activated. On a Google device you’ll see the rainbow lights turn on. Now, the device is recording your command.

Speech to Text
Audio is complicated. It is long. It is noisy. It consumes a lot of resources. Rather than have a computer try to understand audio, it is more efficient to work with text.
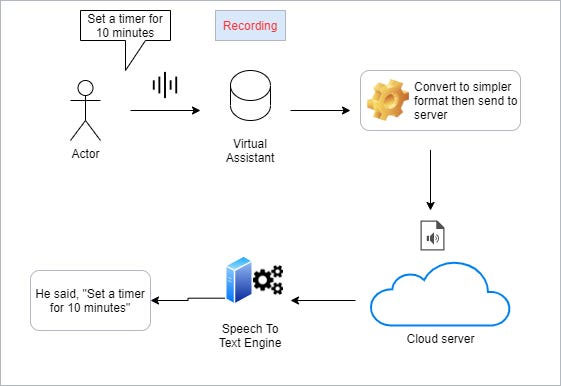
When the device detects a long enough pause after your command, it stops the recording then starts processing. It converts the audio into a more efficient format by constraining it to the human voice spectrum. It is compressed then sent to the company’s servers for further processing. This is how it happens in general. But a company like Google in some cases uses an on-device speech-to-text engine (video) to convert the audio to text.
Let’s imagine that the command is “Set a timer for 10 minutes.” Once the speech to text engine transforms it to text, the next step is to understand what it means. For that we need to classify it one more time.
Classification
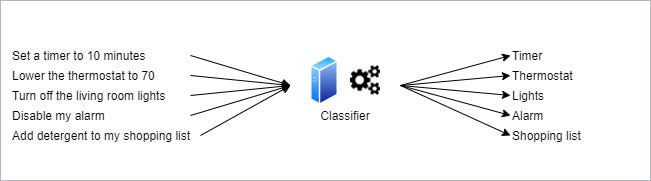
To train a computer to recognize cats, you feed a classifier with thousands of cat pictures. To train a computer to recognize the intent of a message, you feed it with thousands of messages and label them with the intent. For a timer, you can provide these sentences to all point to the same intent.
- Set my timer for 5 minutes
- Set a timer to 8 minutes
- Create a 2 minutes timer.
- Can you set a timer in 10 minutes
There are hundreds if not thousands of variations of this sentence that all mean the same thing. Training a machine learning application to label all this data as “Timer” is trivial. Virtual assistants each support a number of intents and they can be expanded to learn more as new features are added. These intents or actions, if supported, can be used to perform a task.
Depending on the type of command, the server might run the converted text over a natural language processor. This will allow it to extract parameters out of the text. For our example, since it identified the command as setting a timer, we need to know when the timer should go off. So the NLP will read the text and return “10 minutes” as the time parameter. As far as AI is concerned, this is the last time we interact with it.
Performing the task
For our example, the server will return the command “Timer” to our device and will additionally add the parameter 10 minutes to it. The device will use this info to create a timer for 10 minutes.
If the command was “turn off the lights” or a variation of it, the server will return “Turn lights off.” If the device supports the command, it will perform the task. Otherwise it will tell us it doesn’t support it.
As we add more internet connected devices to our network, those that have an integration with our virtual assistant can be connected. It is up to the developers of the device to build the integration and make some commands available. Performing the task itself doesn’t involve AI.
One of the concerns with virtual assistants is that they are recording devices that we put in our homes. What happens when someone starts listening?
Privacy
Is your device recording everything you say and sending it to mother base?
The simple answer is Yes… but it is complicated.
Continuously recording every second of the day and sending it back to the server is highly inefficient. Even large companies like Google or Amazon will be overwhelmed with the amount of data. However, these devices are still recording when in standby mode. Although, they only record a few seconds at a time to check if the trigger phrase has been uttered.
The command you speak after the trigger phrase is recorded and generally sent to the server for further processing. I say generally because there is such a thing as on-device processing. It may not be as accurate in understanding you, but it is much faster. When the data is sent to the server, you can only trust the company that says they discard the data after processing.
For example, Apple claims to only store text transcripts of your command rather than the original audio. You have to opt-in to let them keep the audio to improve Siri. Google will save the audio regardless, and claims that you can delete the data at any time.
There are two scenarios where someone can listen to your recording. When you send a voice command and the device fails to recognize it, it will use this recording for training. A real person will listen to the recording and manually label the data to improve the machine learning model. Law enforcement can also request this data from companies with the proper warrants.
Do note that every company tracks how you use the device. Metrics like GPS, time of day, how many times you use the device, how often you use a command, which 3rd party app you interact with, etc.
At the end of the day, it’s all about trust. You just have to believe that companies do what they claim. When the data is sent to their servers, there is no reasonable way for us to check how it is handled. Personally, I do not use virtual assistants for this very reason.
Of course. The new section integrates smoothly with your existing article's tone and technical depth, while clearly introducing the new paradigm shift brought by LLMs and MCP.
Here is the new section, designed to be placed after your existing conclusion.
Assistants with LLMs: The New Architecture of Voice
The fundamental pipeline I described—trigger word, speech-to-text, classification, action—has been the reliable workhorse for virtual assistants for years. However, the explosion of Large Language Models (LLMs) has fundamentally reshaped this architecture, pushing capabilities closer to that sci-fi ideal of a conversational partner.
The most immediate and dramatic change is that automatic speech recognition (ASR), or speech-to-text, is practically a solved problem. The accuracy of modern cloud-based ASR systems, often powered by LLMs themselves, is staggering. They handle accents, background noise, and complex vocabulary with an ease that was unimaginable just a few years ago. The bottleneck is no longer turning sound into words; it's understanding the intent and nuance behind those words.
This is where the core shift has occurred. In the past, developers built and maintained their own intricate machine learning models for intent classification. This was expensive, required massive labeled datasets, and was brittle—adding a new command meant retraining the model.
Today, the trend is to bypass this entirely. Why train a specialized model to classify "Set a timer for 10 minutes" when a general-purpose LLM can not only understand that but also parse "Hey, can you remind me to check the oven in ten minutes?" as the exact same intent? Developers now commonly feed the transcribed text directly to a powerful, external LLM via an API. The LLM acts as a supremely intelligent and flexible classification engine, returning a structured command like { "action": "set_timer", "duration": 600 }.
This shift is driven by cost and complexity, but not in the way you might think. While running an LLM locally is computationally prohibitive for most devices, the real savings for developers is in development time and maintenance. They offload the immense challenge of natural language understanding to experts like OpenAI, Anthropic, or Google, paying per API call rather than investing in an entire ML engineering team.
This new approach is being supercharged by frameworks like the Model Context Protocol (MCP). MCP provides a standardized way for AI agents (like an LLM-powered assistant) to discover and use the capabilities of other applications. It’s a bridge that makes our applications more "agent-aware."
Think of it this way: before, a smart light bulb had to have a specific, hard-coded integration with Amazon's Alexa platform. With MCP, the light bulb's app can simply expose a set of available actions—turn_on, turn_off, set_brightness—to any MCP-compliant AI agent. This dramatically simplifies integration and opens the ecosystem. Your personal AI assistant could, in theory, operate any application on your computer that supports MCP, from sending a Slack message to analyzing a spreadsheet.
However, a crucial point remains: your application doesn’t magically gain new abilities. MCP isn't magic; it’s a communication standard. Developers still must explicitly implement these actions and expose them to the MCP server. The AI agent can only perform the tasks you’ve empowered it to do. The intelligence to orchestrate those tasks resides in the LLM, but the ability to execute them must still be built by hand.
Before we understood how a virtual assistant works, it all seemed like science fiction. But as we looked closer, we saw a few technologies at work. Speech to text engines, machine learning classifiers, NLP, the internet, and most recently, Large Language Models. It’s a clever integration of these technologies.
The virtual assistant is evolving from a simple command-line interface triggered by voice into a true reasoning engine that can plan and use tools on our behalf. The conversation may finally be coming within reach.


Join the Conversation